今月はじめにScreaming Frog SEOもVer.4.0となりまして、更にイケてるUpdateが数多くされております。
本家でも大きな機能改修としてうたわれている機能の中の1つ、Google Analytics APIとの連携機能。こちらがまた素晴らしい。
Google Analytics APIと連携すると、ある特定ページに対して"全然アクセスが来ない・・・"という受け身から、nofollow等でブロックされていないか?階層は深くないか?などクロール視点からページを分析出来るようになります。検索エンジン側に表示された場合のタイトルや説明文、その他細かい分析を同時に出来るようになります。

2.初回は「Connect to New Account」をクリックします。2回め以降は「Existing Accounts」という欄に自分のメールアドレスが表示されているので、そこを選択して「Connect」ボタンを押します。

3.ブラウザが起動し、認証画面が表示されるので認証画面で「Accept」を押します。
その後「Received verification code. You may now close this window...」というメッセージが表示されたら、ブラウザ側は閉じてアプリ側に戻ります。

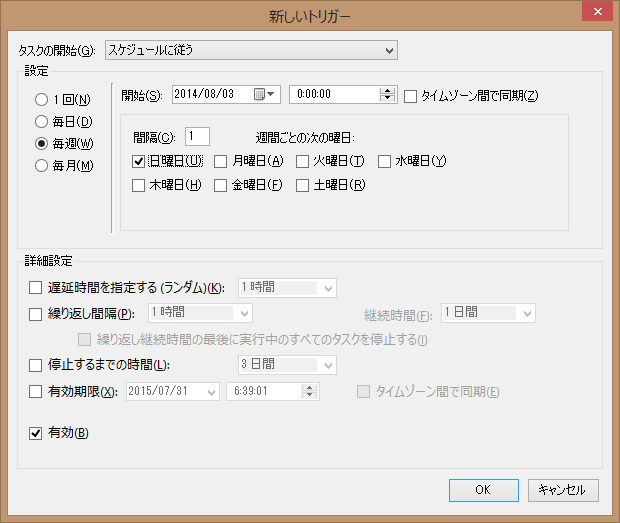
4.Screaming Frog SEO側で連携するプロパティや、最初からセグメントされたデータだけを分析したい場合は、Google Analyticsに最初から用意されているアドバンスセグメントデータを選択出来ますので、そちらで設定を行います。

5.実際にどのmetricsを表示したいか、どのdimensionを選択したいかは各タブで選択可能です。「Date Range」タブは集計期間です。

6.設定が完了すると、「Analytics」というタブが発生し、ウェブサイトをクロール後、Analyticsのデータはそこから確認出来るようになります。

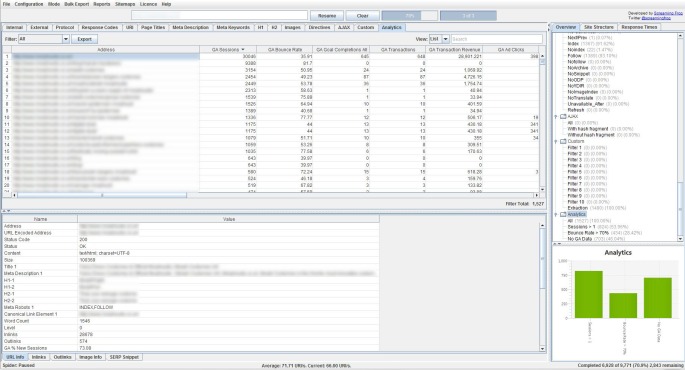
クロール後にAnalyticsのタブを見てみると設定したmetricsデータが表示されています。
 画像 : screamingfrog.co.uk
画像 : screamingfrog.co.uk
【参考】
Screaming Frog SEO Spiderとその使い方・活用法に関する記事はこちら
本家でも大きな機能改修としてうたわれている機能の中の1つ、Google Analytics APIとの連携機能。こちらがまた素晴らしい。
Google Analytics APIと連携すると、ある特定ページに対して"全然アクセスが来ない・・・"という受け身から、nofollow等でブロックされていないか?階層は深くないか?などクロール視点からページを分析出来るようになります。検索エンジン側に表示された場合のタイトルや説明文、その他細かい分析を同時に出来るようになります。
設定方法
1.Google Analytics APIとの連携をする(起動後毎回行う必要があります。)

2.初回は「Connect to New Account」をクリックします。2回め以降は「Existing Accounts」という欄に自分のメールアドレスが表示されているので、そこを選択して「Connect」ボタンを押します。

3.ブラウザが起動し、認証画面が表示されるので認証画面で「Accept」を押します。
その後「Received verification code. You may now close this window...」というメッセージが表示されたら、ブラウザ側は閉じてアプリ側に戻ります。

4.Screaming Frog SEO側で連携するプロパティや、最初からセグメントされたデータだけを分析したい場合は、Google Analyticsに最初から用意されているアドバンスセグメントデータを選択出来ますので、そちらで設定を行います。

5.実際にどのmetricsを表示したいか、どのdimensionを選択したいかは各タブで選択可能です。「Date Range」タブは集計期間です。

6.設定が完了すると、「Analytics」というタブが発生し、ウェブサイトをクロール後、Analyticsのデータはそこから確認出来るようになります。

クロール後にAnalyticsのタブを見てみると設定したmetricsデータが表示されています。
【参考】
Screaming Frog SEO Spiderとその使い方・活用法に関する記事はこちら













.png)


%2B(1).png)